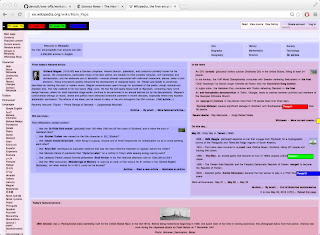
Long story short, here's how to extract your reading list from Amazon (~2 min) and, optionally, transform it into a CSV file (~2 min):
Extract the List of Books
- Log in to your Amazon account
- Click on "Your Account" up top
- Click on "Your Collection" as part of the "Digital Content" box
You'll get to a page that's close but no cigar: books show up as you scroll, but at the same time, old ones get swapped out.
- Hit the print button and wait. And wait. And wait...
- At some point, everything will load. If a printer dialog pops up, cancel it.
- Voila!
You can copy/paste the page into a text editor like Notepad and you'll get a list of records like:
Your Collection
Title: Diffusion of Innovations, 5th Edition
Title: Diffusion of Innovations, 5th Edition
Author: Everett M. Rogers
Date Acquired: January 26, 2010
Rating:
Title: Guns, Germs, and Steel: The Fates of Human Societies
Author: Jared Diamond
Date Acquired: January 24, 2010
Rating:
Don't use something like Word because it'll probably copy the HTML structure behind the page.
Transform Into CSV
Most text editors support regular expressions for fixing up content. For whatever search/replace menu item you have, do the following three steps to turn it into a CSV:
- Clean your data by removing commas
Find: ,
Replace: - Order your data by making each entry a comma delimited line
Find: \r(Title|Author|Date Acquired|Rating):
Replace: , - Clean your data by removing all those "Your Collection" lines
Find: \rYour Collection
Replace:
The rewrites will turn the above entries into just two lines
, Diffusion of Innovations, 5th Edition, Everett M. Rogers,January 26, 2010,
, Guns, Germs, and Steel: The Fates of Human Societies, Jared Diamond,January 24, 2010,
Success! You have scaled the data wall and can plug in your personal preferences to Excel, Goodreads, or your own homebrew algorithm. Let's see how long it takes before Amazon plugs this hole!